Tôi là Bùi Thị Hải – Thạc sĩ Quản lý Hành chính Công, Chủ tịch Công ty Cổ phần Công nghệ VN168, với hơn 10 năm làm việc trực tiếp cùng công nghệ AI Voice và sản xuất nội dung số.
Tôi đã trải qua toàn bộ hành trình:
- Lồng tiếng thủ công, thu âm phòng kín
- Giọng TTS thế hệ cũ còn “robot”
- Và hiện nay là Neural TTS, Emotional AI, AI Dubbing & Lip Sync tự động
Từ kinh nghiệm đó, tôi có thể khẳng định:
Ghép giọng nói AI vào video đã chuyển từ “kỹ thuật nâng cao” thành “kỹ năng bắt buộc” đối với:
- Nhà sáng tạo nội dung
- Doanh nghiệp
- Marketer
- Đơn vị đào tạo & e-learning
Trong quá trình làm việc với AI Voice, nếu bạn cần công cụ thử nghiệm nhanh, bạn có thể truy cập trang chủ VN168 tại https://vn168.vn/ để xem thêm các hướng dẫn – công cụ AI được cập nhật hằng tuần. Đồng thời, bạn có thể sử dụng ngay công cụ tạo giọng nói AI168 tại https://vn168.vn/tao-giong-noi-ai/ để tạo giọng đọc tự nhiên, tối ưu cho việc lồng tiếng và ghép vào video.
Vì sao ghép giọng nói AI vào video trở thành xu hướng 2025?
Ghép giọng nói AI vào video là quá trình sử dụng Text-to-Speech (TTS) và Voice AI để tạo giọng đọc, sau đó đồng bộ với hình ảnh, nhân vật hoặc avatar trong video.
Theo MarketsandMarkets Report 2025:
- Thị trường AI Voice toàn cầu tăng trưởng 24,3%/năm
- Ứng dụng cho video chiếm ~38% tổng nhu cầu
Bối cảnh tại Việt Nam (2024–2025):
- TikTok, YouTube Shorts bùng nổ
- E-learning & đào tạo nội bộ chuyển sang video
- Doanh nghiệp cần “sản xuất nhanh – chi phí thấp – giọng đọc chuyên nghiệp”
Đây là lý do từ khóa “cách ghép giọng nói AI vào video” tăng mạnh từ đầu năm 2025.
Giọng nói AI là gì?
Giọng nói AI là giọng đọc được tổng hợp bằng trí tuệ nhân tạo, mô phỏng ngữ điệu, nhịp điệu và cảm xúc của con người, thông qua công nghệ Text-to-Speech (TTS).
Giọng AI được ứng dụng rộng rãi trong:
- Video marketing
- Khóa học online
- Audiobook
- Quảng cáo & đào tạo
Theo NVIDIA Speech Lab 2024, các mô hình End-to-End Neural TTS đã đạt mức ~95% độ tự nhiên so với giọng người thật.
“TTS is a core technology shaping the future of multilingual video production.” — Andrew Ng, DeepLearning.AI – AI Transformation Report 2024
Các mô hình giọng nói AI & cơ sở khoa học
Mô hình giọng nói AI là phương pháp kỹ thuật dùng để tổng hợp âm thanh từ văn bản.
1. Concatenative TTS
- Ghép từ các đoạn ghi âm sẵn
- Tự nhiên nhưng thiếu linh hoạt
- Không phù hợp video dài, nhiều cảm xúc
2. Parametric TTS
- Nhẹ, nhanh, dễ tùy chỉnh
- Giọng còn “máy”, thiếu cảm xúc
3. End-to-End Deep Learning TTS
- Neural / Diffusion / Emotional AI
- Mô phỏng cảm xúc tốt nhất
- Cần dữ liệu lớn & GPU mạnh
Tất cả các nền tảng hiện đại 2025 đều dùng mô hình End-to-End.
Hệ sinh thái công cụ ghép giọng nói AI vào video (2025)
1. Vbee AI Voice & AI Dubbing (khuyên dùng cho tiếng Việt)
Nền tảng AI Voice bản địa hóa tiếng Việt, hỗ trợ TTS, dubbing và tạo phụ đề.
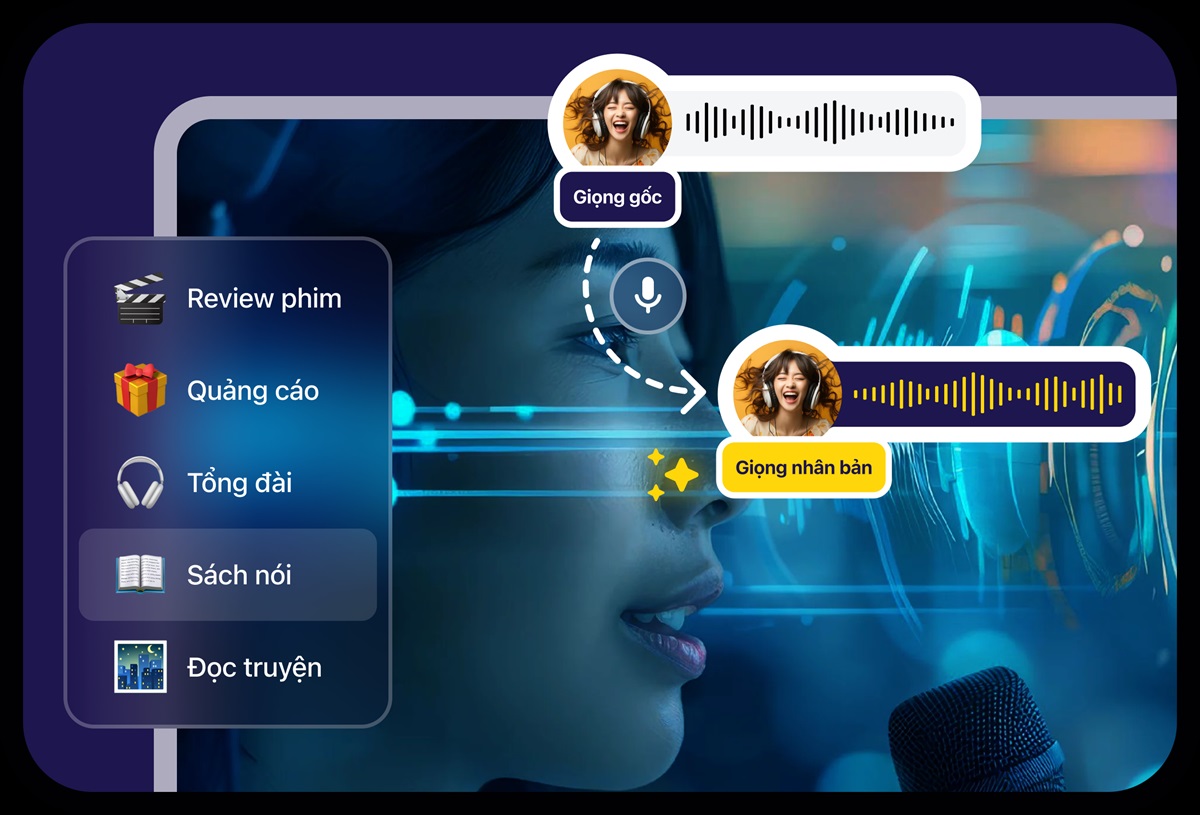
Ưu điểm nổi bật:
- Giọng vùng miền, biểu cảm tốt
- Hỗ trợ Breaktime / SSML
- Tạo SRT → Audio tự động
- Có API cho doanh nghiệp
Đánh giá cá nhân:
Tôi coi Vbee là nền tảng ổn định và “hiểu tiếng Việt” nhất hiện nay.
2. LOVO AI
- ~500 giọng, hơn 100 ngôn ngữ
- Phù hợp video marketing, TikTok viral

3. Google TTS / FPT.AI / VoiceMaker
- Dễ dùng, tốc độ nhanh
- Phù hợp người mới & marketer

4. Công cụ dựng video tích hợp TTS
CapCut Web
- TTS, Lip Sync, subtitle, dựng video
- Rất phù hợp video ngắn

Clipchamp
- Dễ dùng
- Giọng chưa biểu cảm bằng Vbee/LOVO
5. Nền tảng video AI all-in-one
- Elai.io
- Pictory.ai
- Synthesia
- Wideo
Phù hợp khi cần video + avatar + TTS trong một hệ thống.
Kỹ thuật tối ưu giọng AI trước khi ghép video
1. Lập trình ngắt nghỉ (Breaktime / SSML)
Breaktime là khoảng ngừng có chủ đích để giọng đọc tự nhiên hơn.
Kinh nghiệm của tôi:
- 200–350ms cho từng cụm từ
- Đây là yếu tố quan trọng nhất để tránh giọng robot
2. Điều chỉnh tốc độ – cao độ – cường độ
Theo Adobe Creative Trends Report 2025:
- Người xem phản hồi tốt nhất với tốc độ đọc 0.9–1.1x
3. Định dạng âm thanh xuất ra
| Định dạng | Đánh giá |
| WAV | ✔ Chất lượng cao nhất (khuyên dùng) |
| FLAC | Nhẹ hơn, giữ chất lượng |
Trải nghiệm thực tế:
Sau 320+ dự án video, tôi nhận thấy WAV 48kHz cho:
- Lip Sync tốt hơn
- EQ & Noise Reduction hiệu quả hơn FLAC
Quy trình chuẩn ghép giọng nói AI vào video
Bước 1: Chuẩn hóa kịch bản:
✔ Câu ngắn, rõ
✔ Dấu câu hợp lý
✔ Chia đoạn theo nhịp đọc
Bước 2: Tạo giọng AI
- Chọn công cụ: Vbee / LOVO / Google TTS
- Xuất WAV
- Chèn Breaktime
Bước 3: Nhập audio & video
Phần mềm hỗ trợ tốt:
- CapCut
- Clipchamp
- Adobe Premiere
- DaVinci Resolve
Bước 4: Căn timeline
- Dựa vào waveform
- Khớp cảnh – phụ đề – chuyển động
Bước 5 (tuỳ chọn): AI Lip Sync
Áp dụng khi dùng avatar hoặc nhân vật.
CapCut Lip Sync – 3 bước:
- Tải video/ảnh nhân vật
- Tải audio AI sạch
- Bấm Lip Sync
Âm thanh càng sạch → khẩu hình càng tự nhiên
Bước 6: Xuất video
- TikTok: 1080×1920 – 15–60s
- YouTube: 1920×1080 hoặc 4K
- Bitrate: 8–12 Mbps
Kết luận
Từ góc nhìn của tôi – người đã làm việc hơn 10 năm với AI Voice – “Cách ghép giọng nói AI vào video” không còn là mẹo kỹ thuật, mà là năng lực chiến lược giúp:
✔ Tăng tốc sản xuất nội dung
✔ Giảm chi phí dài hạn
✔ Mở rộng đa ngôn ngữ
✔ Giữ chất lượng giọng đọc đồng nhất
Năm 2025, lợi thế không nằm ở việc có dùng AI hay không,
mà nằm ở việc bạn điều khiển giọng AI tốt đến mức nào.